Case Studies¶
All code is here: https://github.com/Python-Test-Engineer/eval-framework
First steps¶
We need to understand what the app does and what the workflow is.
We identify the Agentic points where we use LLMs and then apply logging.
- What does a satisified user look like?
- What would a disappointed user look like?
- How do we define a successful app from our point of view?
We need to make each agent self-evaluating. That is, we need to export to CSV input|output|context|tool_use|metadata.
Then we can add references if we have them and run our evals.
We will do this manually to get a sense of what we need to implement and if possible scale up with automations and LLM as judge.
Case Study 1¶
Langgraph¶
In this first case study, we use a sample Langgraph app located in src/case_study1/langgraph/app_article_writer.py
Evals where done after the app was built so we idendify the Agentic points where we use LLMs and then apply logging.
There are 4 LLM instances and this is where we do our Agentic Evals.
EVAL01:
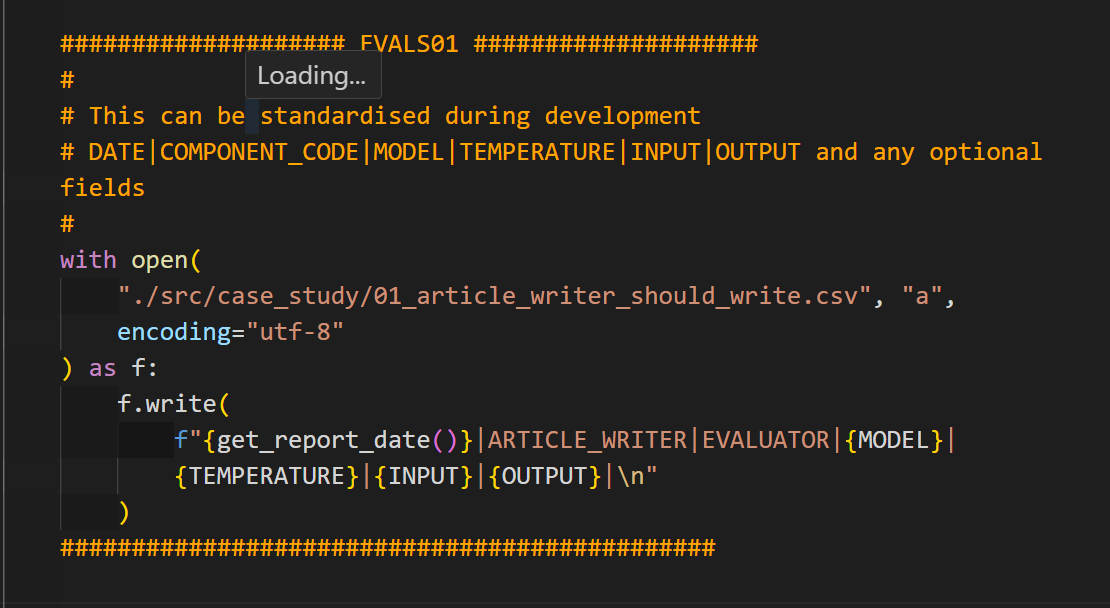
We log to 01_article_writer_should_write.csv and do the same for the other 3 evals.
Case Study 2¶
OpenAI Agents¶
This is a case study using a Deep Research clone app by Kody Simpson.
I coded it up without the 'Follow up' on research items.
The repo is https://github.com/Python-Test-Engineer/llm-evaluation-framework
Located in src/case_study2/deep_research it uses the OpenAI Agent SDK.
It enables us to use an actual app to set up Evals.
uv run ./src/deep_research/main.py
Evaluating¶
With the app is we will go through a generic sequence of how we carry out evals:
- What does the end user want?
- How can we evaluate and monitor to ensure our client's needs and wants are met?
- What and where do we log?
Case Study 3¶
Tool calling¶
We have a separate case study for tool calling to avoid cluttering the other case studies.
We want the end branch of our app where we have the lass Agentic component.
We can then combine all case studies as sub graphs.
Evaluations¶
For tool calling we want to evaluate:
- Was the right tool called for the right input?
- Were the arguments correct?
- Did the tool produce the right output?
If the tool uses another agentic function the we would evaluate that subgraph but in our case study we are not using any agentic subgraphs and any functions used would be deterministic in nature.