Overview¶
"How do you make a blueberry muffin? You put the blueberries in at start not stuff them in at end." - Accessibility speaker.
It is part of the development lifecycle supporting the developer and all othe rstake holders.
It is most useful to ask stakeholders what is important to them and how they will assess the effectivenes of the Agent.
Evaluations¶
-
Code based - traditional testing
-
LLM as Judge - specialist LLMs to rate tone, completeness, no PII, matrix analysis, gender bias etc as well as the confusion matrix of input-output-context-reference.
-
ML analysis - we may use ML models to compute a metric.
-
Human Annotations.
Numerical evals are hard for LLMs so we use more qualitative measures.
Start with Human Evals and scale with LLM Judge. This seems the top recommendation from those in the field.
Human evals will reveal what we need to test.
LLM Judge will enable scaling - we ask the LLM for its reasoning for its grade.
The experts say this will reveal many things, notably whether the LLM and us are not on the same page in the evaluation process. We can then change the prompt.
Getting judge to give its reasoning is vital to check judging is on the mark.
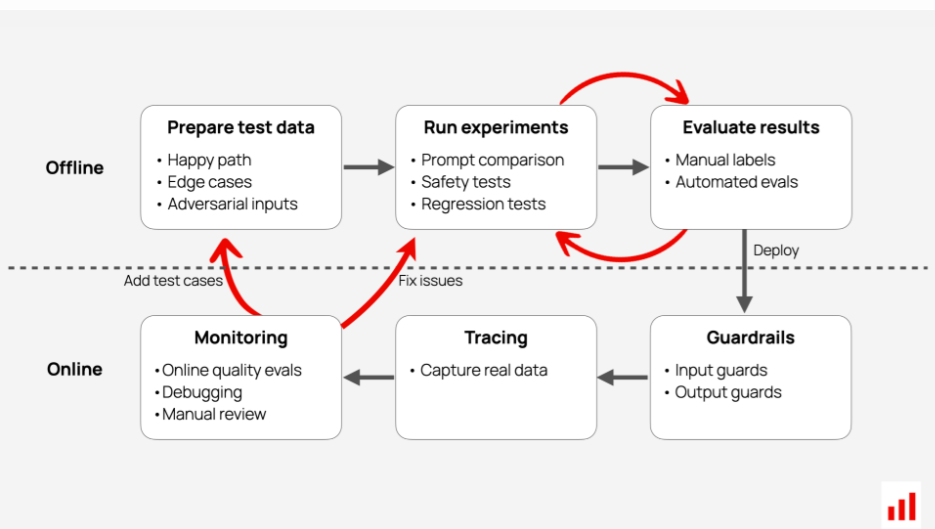
Scoping¶
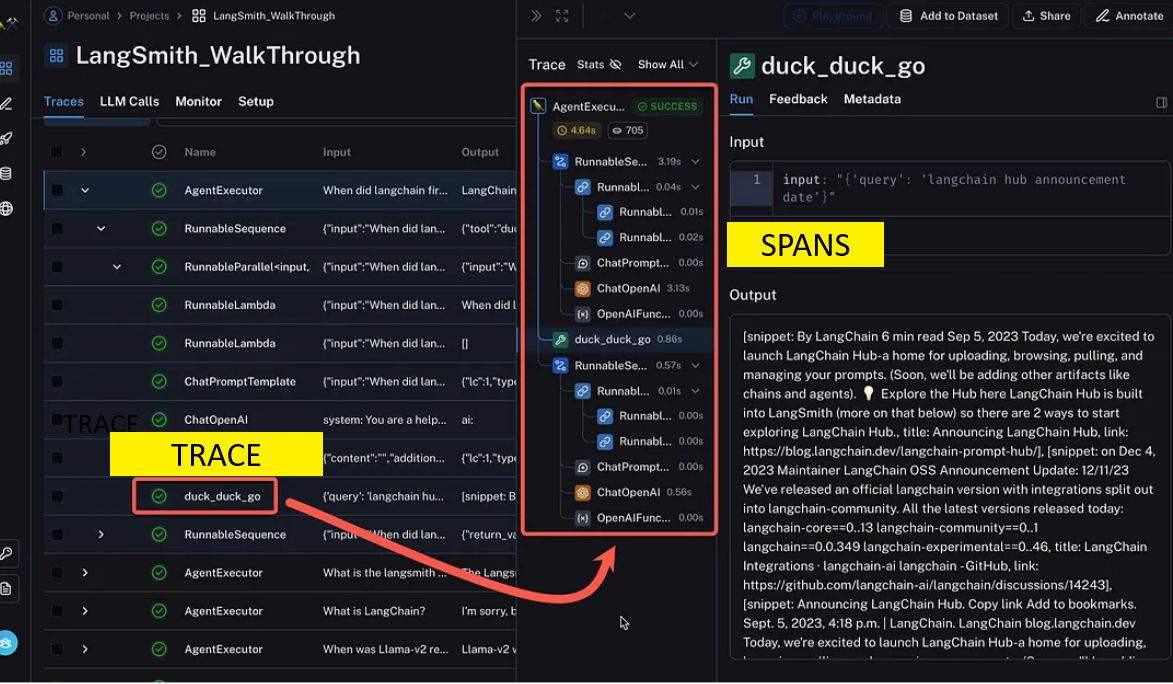
- Trace - the run
- Span - items within the run
Telemetry¶
CORE DATA:
- Some of these are optional
-
We may use a code to identify the unit under test, e.g
app_unit_test_type -
RUN_ID (unique run id to group all traces in a workflow)
- USER_ID
- ENVIRONMENT (dev/staging/prod)
- DATETIME
- TRACE
- SPAN
- MODEL
- MODEL_KWARGS (temperature etc)
- INPUT
- OUTPUT
- CONTEXT
- TOOL_CALL
- TOOL_INPUT
- TOOL_OUTPUT
(custom data) - WHAT_DEV_ADDS
These CSVs are appropriately named and will then have REFERENCE ground truth added to provide an dataset for analysis.
We can also run evals with no references. We use LLM as judge to determine the eval.
There are a number of libraries I like:
- Evidently AI - favourite of mine as it made Evals easy and enjoyable.
- Deep Eval
- RAGAS
LLM as Jury¶
LLM as a jury involves using large language models to simulate jury decision-making processes, evaluating evidence and reaching verdicts like human juries, though with significant limitations around bias and moral reasoning.
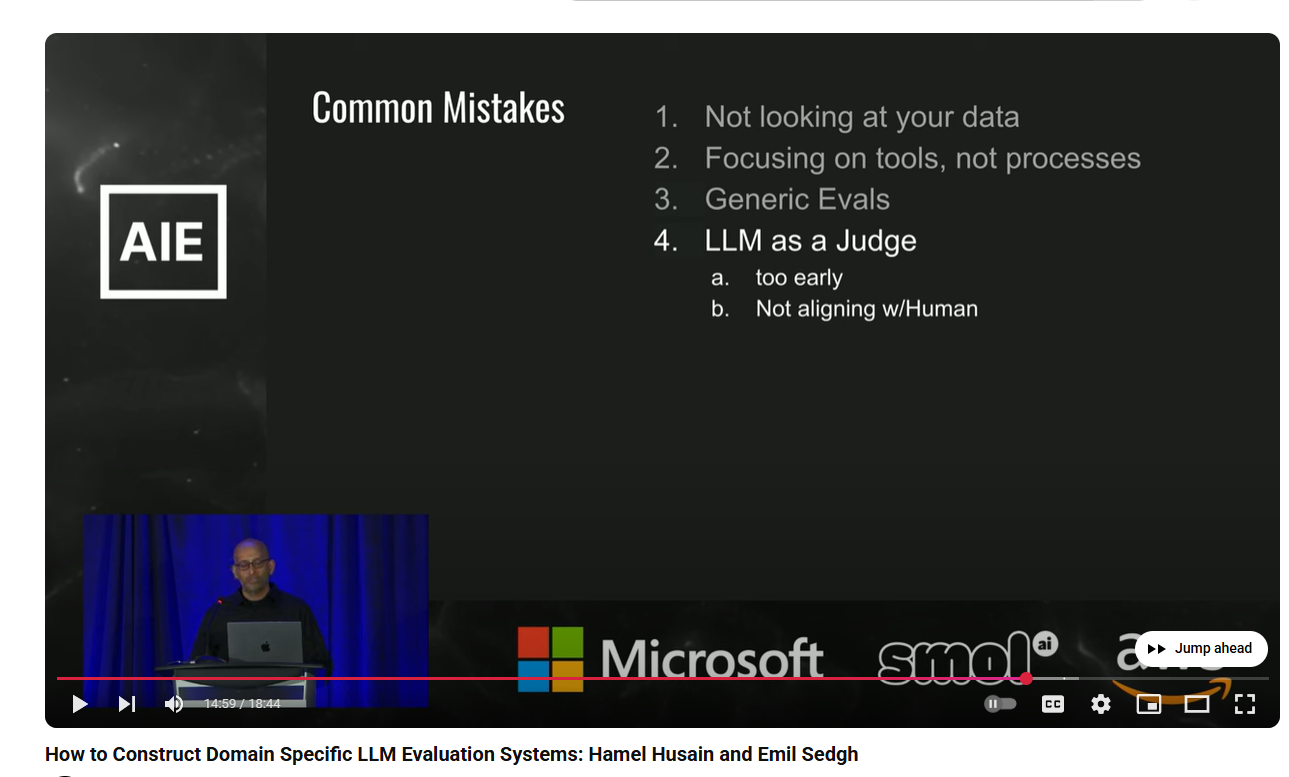
Common mistakes¶
Essence¶
https://hamel.dev/blog/posts/llm-judge/#its-not-the-judge-that-created-value-after-all states:
